
ImprovBot is trained – solely – on the corpus of 28311 previous Edinburgh Fringe shows, including their titles and their 100 word descriptions, that appeared in the programme between 2011 and 2019. It doesn’t rely on any other statistical input – which means it is, in essence, trying to imitate the linguistic walled garden of the Fringe programme brochures. Looking at this corpus can give some insight into The Bot’s output (while also perhaps helping others to formulate their own show descriptions so they stand out from the crowd somewhat!). So we threw the corpus The Bot has read and re-read into Voyant Tools – a web-based reading and analysis environment for digital texts to see what we could learn about its contents.

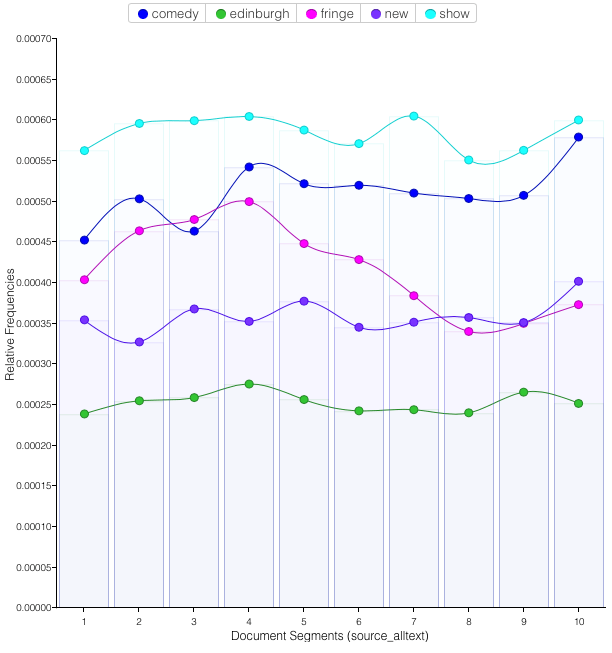
The descriptions and titles from the 28311 shows give us 2,091,000 total words and 65,488 unique word forms. The most frequent of these words are unsurprising: show (12191 occurences); comedy (10651); fringe (8697); new (7478); edinburgh (5265); music (5086); world (4914); life (4821); award (4645); best (4579). Not surprisingly, these are fairly constant over time, with perhaps a dip in the latter descriptions of being at the Fringe (the venue should be obvious, indeed).
What is surprising is the corpus’ vocabulary density: the ratio of 0.031 means that there is an incredibly low ratio of total wordcount to unique words. In fact, 26,122 words are only ever used once in the descriptions (something we’d call a “hapax legomenon”), such as bitcoins, bumblewasp, and numpty. It’s worth noting in comparison that, although calculating vocabulary size in humans is a complex art, a recentish 2013 study shows that college students only know 10,000 words on entry to university and approximately 11,000 words in their final year. The word list ImprovBot has to draw on is therefore complex, huge and overall interesting, and much larger than the average vocabulary of a native English speaker. There’s a lot of names, regional slang, and creative use of language in there, too. Scots is in thecorpus – Bampot (4), raj (3), jobby (3). You can also use the tool to spot cultural trends and tropes: Game of Thrones (18, most popular in 2015/16), Mad Men (3), Agatha Christie (7), Spice Girls (15), etc etc.
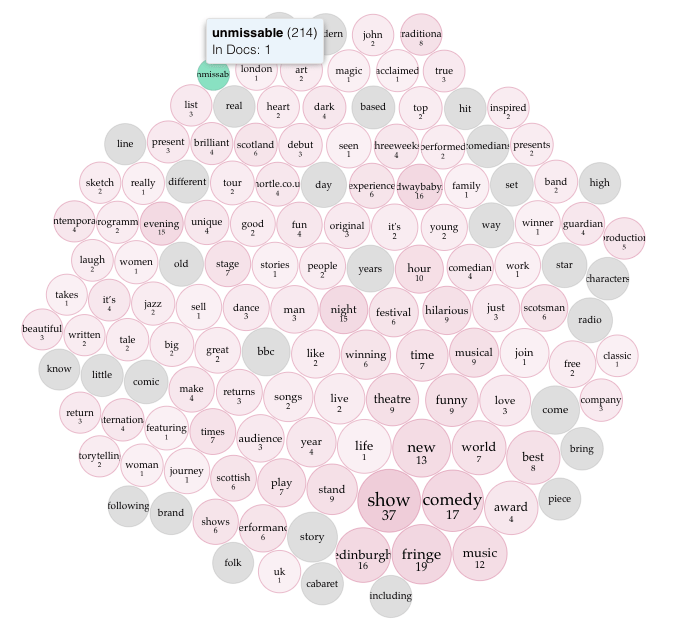
What about the word unmissable? It actually only occurs in 214 show descriptions, with “don’t miss” appearing in 212. One of the interesting things Voyant allows is to see the words that are used around such a word – the collocates – unmissable is most used near show, comedy, Edinburgh, fringe, new and music.
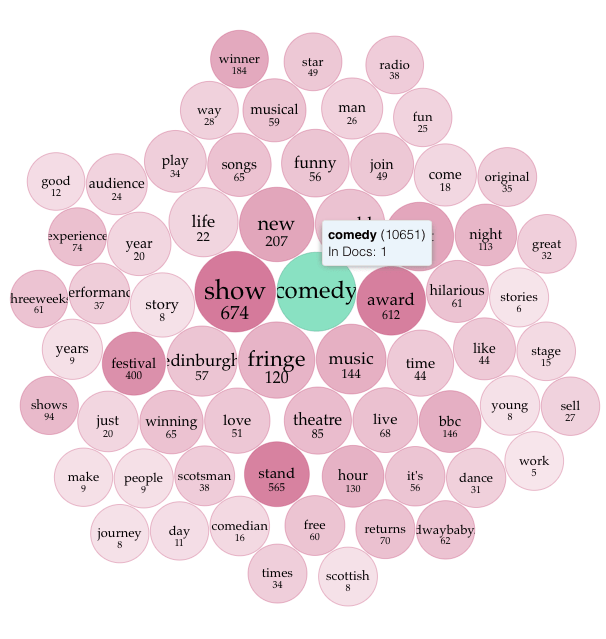
We can do the same for the word “comedy” – people do like to talk about their awards. Obviously, if you are a fan of the Fringe, you could probably have guessed all this.
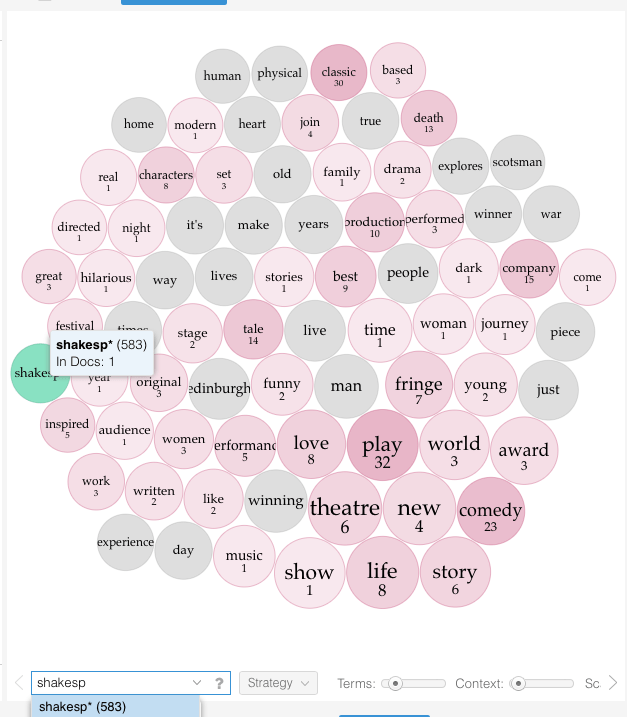
What about the 7474 shows in the corpus that self identify as “theatre”? There’s 570,561 total words and 34,827 unique word forms in that slice. Here they are visualised, below.
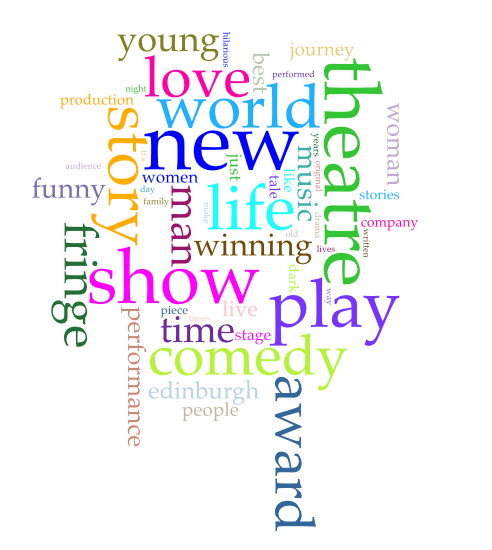
There’s 583 mentions of some derivation of Shakespeare/Shakesperian, 131 mentions of Hamlet, and 44 Midsummer Night’s Dreams. There’s only one Spartacus, which seems a bit wrong (see what I did there). 19 Seagull’s, 7 Peer Gynt’s.
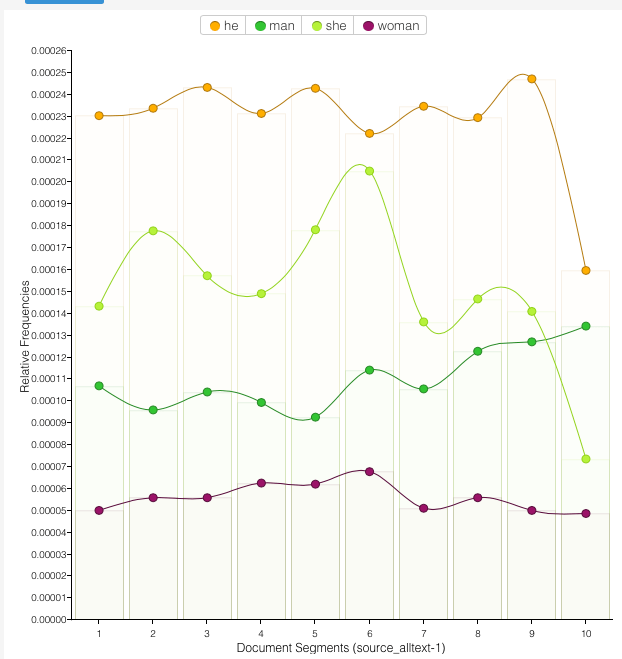
So far, so obvious. These tools are most useful when you drill down to look at particular vocabulary, or examples, to look for difference and nuance. A common thing to look at is bias, particularly around gender. For example, we can look up he, she, man and woman (while other genders are and should be available, this shows the binary which most of the world still tries to reinforce). We can see there’s a lot more mention of he (4749) than she (3146) in the corpus, and many more mentions of man (2299) than woman (1163). Hmmmm. Do better for equality, Fringe show description writers!
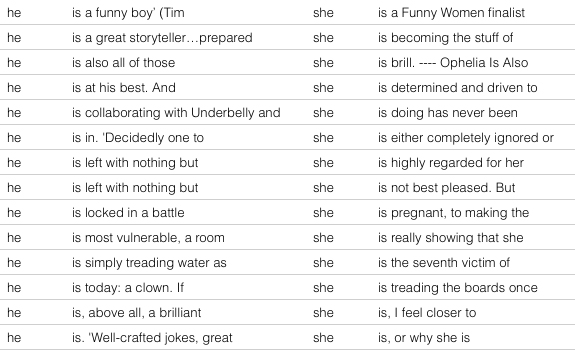
We can also use Voyant to look at the correlates – words around – words. How do “he is” and “she is” differ? You can write linguistic dissertations on this stuff…
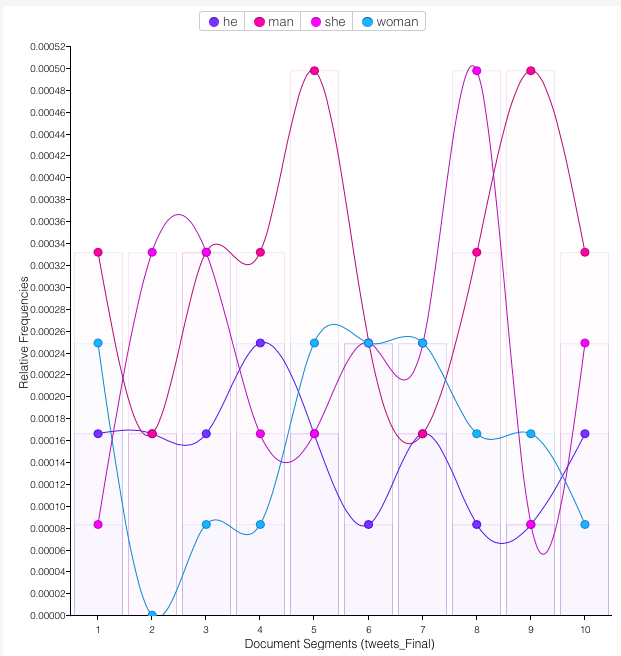
And how does that linguistic bias leak through, then to the outputs of ImprovBot? If we take the corpus of first shows that we produced, after curation? In our initial run, we produced 12,063 total words and 2,644 unique word forms, with a word density of 0.219, so – fewer unusual or weird words, in our much smaller word set. We can see that although we’ve still got more man (39) than woman (19) we actually have more she (29) than he (18). You have to watch how you control parameters/temperature, and curation practices, to address any underlying biases in data (which, is implicit, given the world around us which has produced it). Not reproducing and reaffirming biases has to be a conscious thing, although we may also have more work to do to get the he/she balance. Bias in = bias out.
This type of linguistic analysis and visualisation can be a useful tool to think about how language is used, and what is expected in that genre. If you only have 100 words to fill up a show description, will you stand out if you describe it as a “best new comedy award-winning Edinburgh fringe show, about life”? Does the audience expect that, though, to situate it? It’s probably worth throwing in some old tried and tested to provide the framework, but some newness, and originality, in there too. Bring out your slang, your local, your unique. Be more aware of historical and implicit biases. Be the change you want to see in the Fringe. It’s the only way to stand out.
The Edinburgh Festival Fringe Society are open to approaches from researchers who want access to their data for non-profit, scholarly activity, if you fancied trying a more detailed analysis yourself. Ask via the Edinburgh Festival City API.
